
从搬运 DTO 到 CRUD 在如今的开发模式下,服务端程序员离原始数据越来越远,和农夫山泉一样,他们不生产数据,他们只是 DTO 的搬运工。从各种 service 中获取数据,再使用 Lambda 进行拆分组装成为了他们的日常工作。
然而,随着各家大厂都开始“降本增效”,DTO 的搬运工越来越不具备竞争力,“技多不压身”变成了下一阶段的 OKR,于是「CRUD 工程师」便“应运而生”了。
本文的内容便是围绕着 CRUD 中的 R(ead)展开的。
数据检索的玄铁剑——索引 在现实生活中,如果你想使用新华字典查询一个字,在没有背下来具体页码的情况下,第一步多半是打开目录,根据拼音首字母快速的锁定目标数据所在的位置范围。如下图 👇
索引究竟是什么? 百度百科是从数据库的角度出发给出了一个索引的定义,维基百科也并没有为 CS 中的索引做一个概述,而是细分了多个领域来介绍 👉https://en.wikipedia.org/wiki/Index
本质上,索引是一种用于提高数据检索效率的技术,它可以是一种复杂的数据结构(Hash,B Tree……),也可以就是一个简单的下标。
为了更好的理解索引,先看一下没有索引的查询是什么样的?
没有索引的查询 上班路上,你和一个长发姐姐擦肩而过,来到公司,惊喜的发现她竟然也在这栋楼上班,此时电梯停在了 3 楼,小姐姐出去之后你便继续乘到了 6 楼,虽然你一直写着代码,但此时你的心早已飞去了三楼。
OK,那么问题来了,如果你想再见到那个长发姐姐,第一想法是什么?一定不是发表白墙吧。
在纠结了半天之后,最后你还是选择了最原始但也是最简单的办法,去三楼的工位一个个找。
你一边遍历着所有工位上的人,一边幻想着等再见面时的场景。终于皇天不负苦心人,在你离她还有六个工位的时候,你见到了她。就在你以为终于能发出“一起喝咖啡”的邀约时,一位靓仔从你的后面“瞬移”到她面前,然后说出了那句“有时间一起喝咖啡吗?”。
事了拂尘去,靓仔最后回头看了你一眼,然后说到:“小伙子,爷有索引”。
微观视角的索引——什么才是有意义的索引 上面这个例子就是一个很典型的场景,在没有索引的情况下,查询就变得简单粗暴——全表扫描。查询耗时完全由数据量决定,海量数据的查询基本无法满足需求。 由于遍历的时间复杂度是 O(n),那么为了让索引变得有意义,其时间复杂度必定是小于 O(n)。
常刷算法题的小伙伴们都知道,经常出现查找的两类数据结构就是数组和树,其实也对应着两种最常见的索引。
哈希索引:复杂度为 O(1) 树索引:复杂度为 O(log n) 哈希索引原理是根据属性组合直接通过哈希函数计算出结果数据的地址,一般来说更快(包括建索引的效率和查询效率),具体性能依赖于数据集和哈希函数的匹配程度。
树索引原理是基于属性组合建立树再根据二分查找定位数据,虽然建索引和查找速度都慢一些,但优势是可以支持范围查询和 front-n 属性匹配(前缀匹配)的查询。其中 front-n 属性的查询意思是,属性组合中的前 1 到前 n 个属性组成的子组合的查找。例如属性组合是 A-B-C,那么树索引可以支持 A、A-B、A-B-C 三个属性组合的查找。
基于这两类数据结构,可以延伸出非常非常多具体类型的索引,这里就不过过阐述了。接下来我们把格局打开,来看看宏观视角下的索引是如何运用的。
宏观视角的索引——全局索引/本地索引 独立于源数据之外,索引的存储自然也是要保存在另一张表中。提供主键查询的表称为主表,满足绝大多数的业务查询场景。提供非主键查询的表称为二级索引表,主表是一级索引表。
...
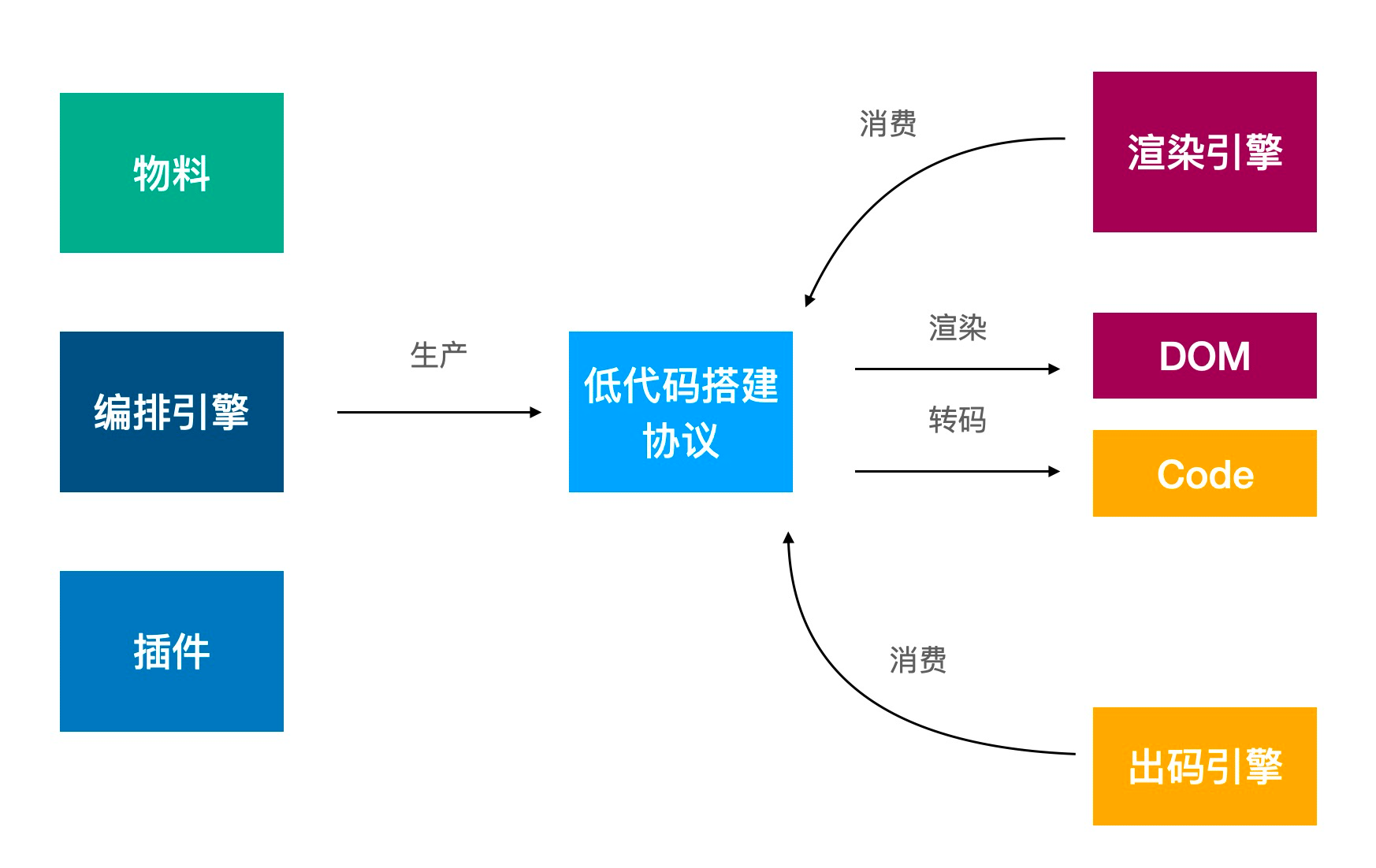
前言 本文是笔者在团队内部做分享整理的资料的一部分,本次分享主要是站在一个服务端开发的视角对(前端)低代码平台的一些调研,已经剔除了一些敏感数据和信息,可放心食用。
太阳底下无新事 Dreamweaver -> Low-Code 将时钟拨回到 20 年前,那个时候的开发者对于 html/css/js 还处在望而生畏的阶段,Dreamweaver 的出现仿佛让他们看见了曙光。通过简单的拖拽就可以实时预览编排的页面,点击按钮就可以自动生成对应的前端代码,配置好机器信息就可以一键部署访问…… 这些特性让无数开发者趋之若鹜,然后现在他的境况
现如今,Dreamweaver 几乎已经退出了历史舞台,但 Low-Code 似乎又有卷土重来的迹象……
Low-Code 是什么? A low-code development platform (LCDP) is software that provides a development environment used to create application software through graphical user interfaces and configuration instead of traditional hand-coded computer programming.
一句话概括就是 👉 用 GUI+配置取代传统手工编码 技术上,实现低代码平台的关键要素是模型驱动设计、代码自动生成和可视化编程,通过这些手段来隐藏下层的代码细节。
更激进的—— No-Code(零代码) Low-Code 更激进的演进方向是 No-Code,主要的差异点如下:
平台用户:任何业务人员都能使用无代码平台,而低代码平台面向开发者(尽管专业要求不那么高)
核心设计:无代码平台倾向于让用户通过拖拽或简单的表达式来操纵完成应用设计,而低代码平台更倾向于通过人工编码来指定应用程序的核心结构
用户界面:无代码平台为了简化应用设计,一般只支持内置的 UI 库,而低代码平台可能会提供更灵活的 UI 选项,但代价是需要额外编码,使用上的复杂性有所增加
为什么目前低代码只在前端领域很火? 被资源化的前端开发者 工作量大,重复性工作较多,因此生产效率成为了必须要解决的问题。
...

前言 对于一个 Java 开发者来说,Lombok 应该是使用最多的插件之一了,他提供了一系列注解来帮助我们减轻对重复代码的编写,例如实体类中大量的 setter,getter 方法,各种 IO 流等资源的关闭、try…catch…finally 模版等,虽然可以通过 IDE 的快捷帮我们生成这些方法,但这些冗长的代码仍会影响代码的简洁性与可阅读性。 如今,随着使用者数量越来越多,Lombok 甚至成为 IDEA 的内置插件了(2020.3 版本+),可见其影响力。
但不知道使用 Lombok 的你,是否思考过这种自动生成代码究竟是什么原理呢?🤔 这些代码又是怎么产生的呢?而这就是本文要展开介绍的内容了。
Lombok 的安装与使用网络上相关的介绍已经很多了,这里就不多说了,自行查阅相关资料即可。
注解解析的两种方式 关于注解,我在之前的文章里有过详细的介绍,在解释 Lombok 的原理之前,推荐你先阅读 👉《给编译器看的注释——「注解」》 这里主要回顾一下 Lombok 注解的解析方式。
运行时解析 这是最常见的注解解析的方式,运行时能够解析的注解,必须将@Retention设置为RUNTIME,这样就可以通过反射拿到该注解。 例如使用最多的@RequestMapping注解就是一个运行时注解。
@Target({ElementType.TYPE, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented @Mapping public @interface RequestMapping { String name() default ""; @AliasFor("path") String[] value() default {}; @AliasFor("value") String[] path() default {}; RequestMethod[] method() default {}; String[] params() default {}; String[] headers() default {}; String[] consumes() default {}; String[] produces() default {}; } 运行时注解的解析原理也很简单,在 java.lang,reflect 反射包中提供了一个接口 AnnotatedElement,该接口定义了获取注解信息的几个方法,Class、Constructor、Field、Method、Package 等都实现了该接口,对反射熟悉的朋友应该都会很熟悉这种解析方式。相关的例子在之前的文章中有介绍过,这里不赘述了。 那 Lombok 的注解也是这种原理吗? 翻开源码,我们可以看到@Data这个接口 RetentionPolicy 是SOURCE级别的,也就是说,在代码编译的时候,相关的注解信息就已经丢掉了,并不会被加载进 JVM 里,那么为什么我们又会在 Compile 代码的时候看见那些 get/set 方法呢?这就不得不说另一种注解解析方式了——编译时解析
...
抛砖引玉 在文章开始前,先看看一个常见的情况 👇
在集团内进行开发时,通常会遇到不同组之间的合作,如果是同一个组的前后端,因为交互请求都是在同一个 「域」 内发生的,所以一般不会存在跨域问题。但如果未做处理,直接从 a.alibaba.com 请求 b.alibaba.com 的接口,就会出现跨域的问题,这是因为浏览器对于不同域请求的限制问题,其实跨域的问题很好解,只要设置了正确的请求头即可,具体的可以参考我的这篇文章 👉《一次跨域问题的分析》
但这是访问不需要登录的接口,那如果是从 a.alibaba.com 访问 b.alibaba.com 下的一个需要登录的接口呢?又该如何解决呢?
下文以 A 站点指代 a.alibaba.com,B 站点指代 b.alibaba.com
单系统登录 对于一个 web 应用来说,通信协议通常是 HTTP 协议,该协议是无状态的,也就是说,在请求与请求之间是不会产生关联的。这也就意味着,任何用户都能通过浏览器访问服务器资源,且不会打扰到其他用户。如下图所示 👇
如果想要保护某些资源,比如一些珍贵的学习资料,那就必须限制浏览器的请求,对于服务端来说就是要知道发出这个请求的人是谁,也即让请求变得有「状态」,只不过既然 HTTP 协议无状态,那就让浏览器和服务器之间共同维持一个状态吧,而这就是最常见的——会话机制。
Cookie 和 Session 在会话机制中,最重要的就是 Cookie 和 Session 了,Session 好理解,服务端保存的用来维护某一个用户的状态,浏览器只需用某种方式记录下这个会话的 ID 然后之后每次请求携带即可,想必有小伙伴会发出疑问了,既然是给浏览器携带参数,那么直接在请求参数里携带不是最简单的吗?
的确,将会话 id 作为每一个请求的参数,服务器接收请求自然能解析参数获得会话 id,并借此判断是否来自同一会话,这个思路当然是可以的,只是这种做法的缺点也十分明显,就是请求的 URL 会变得非常长,隐秘性也很差。
而 Cookie 是浏览器用来存储少量数据的一种机制,数据以”key/value“形式存储,并且浏览器发送 http 请求时自动附带 Cookie 信息。此时,有 Cookie 参与的登录请求的流程就变成了下面这样 👇
Cookie 和 Session 的使用原理基本如此,至于这么设置 Cookie,怎么通过 Cookie 校验 Session 就不是本文要说的内容了。有兴趣的可以查阅相资料。
多系统登录 不知道你有没有留意过,如果你在浏览器中登录了百度网盘之后,再打开百度贴吧时就会发现此时你已经登录成功了,这种情况就是本节要说的多系统登录了。
...

前一篇文章我们介绍了 Java 中的两个常见的序列化方式,JDK 序列化和 Hessian2 序列化,本文我们接着来讲述一个后起之秀——Kryo 序列化,它号称 Java 中最快的序列化框架。那么话不多说,就让我们来看看这个后起之秀到底有什么能耐吧。
Kryo 序列化 Kryo 是一个快速序列化/反序列化工具,依赖于字节码生成机制(底层使用了 ASM 库),因此在序列化速度上有一定的优势,但正因如此,其使用也只能限制在基于 JVM 的语言上。
网上有很多资料说 Kryo 只能在 Java 上使用,这点是不对的,事实上除 Java 外,Scala 和 Kotlin 这些基于 JVM 的语言同样可以使用 Kryo 实现序列化。
和 Hessian 类似,Kryo 序列化出的结果,是其自定义的、独有的一种格式。由于其序列化出的结果是二进制的,也即 byte[],因此像 Redis 这样可以存储二进制数据的存储引擎是可以直接将 Kryo 序列化出来的数据存进去。当然你也可以选择转换成 String 的形式存储在其他存储引擎中(性能有损耗)。
由于其优秀的性能,目前 Kryo 已经成为多个知名 Java 框架的底层序列化协议,包括但不限于 👇
Apache Fluo (Kryo is default serialization for Fluo Recipes) Apache Hive (query plan serialization) Apache Spark (shuffled/cached data serialization) Storm (distributed realtime computation system, in turn used by many others) Apache Dubbo (high performance, open source RPC framework) …… 官网地址在:https://github.com/EsotericSoftware/kryo
...

我之前在《聊一聊 RPC》中曾提过什么是序列化和反序列化,当时有说过之后要单独抽出一期来详细聊聊序列化,没想到这一拖竟然拖了一年多,现在来把这个坑补上。由于篇幅较长,本文先主要介绍两种常见的序列化方式——JDK 序列化和 Hessian 序列化。
序列化是什么(What) 百度百科对于 「序列化」 的解释是:
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。
这么说太抽象了,举一个例子:你如果想让一个女孩子知道你喜欢她,你可以给她写情书,这样 「喜欢」 这种状态信息就变成了 「文字」 这种可以存储或传输的信息。
至于怎么把“情书”送给女生就有很多种方式了,我在《聊一聊 RPC》中已经有写过了,感兴趣的读者们可以点击阅读。
所以,简单理解序列化就是将“对象”存储的信息保存到某个“文件”中,之后再通过某种方式读取“文件”转换成对象。在 Java 中,序列化其实就是把一个 Java 对象变成二进制内容,本质上就是一个 byte[]数组。
既然有序列化,那么就会有反序列化,在上文的例子中,如果女孩通过情书中的文字明白了男孩的喜欢,这就是一种反序列化。在 Java 中,将一个 byte[]数组重新变成 Java 对象就是一种反序列化。
为什么要序列化(Why) 这个时候肯定就有人会问了,直接把对象作为参数传递不就可以了吗?为什么还要多此一举把对象变成“文本”,然后再将“文本”变成对象?
我们知道,Java 创建的对象都是存在于 Java 虚拟机中,也即 JVM 中,那么 JVM 又在哪里呢?
JVM 是 Java 程序运行的环境,但是他同时是一个操作系统的一个应用程序,即一个进程。他的运行依赖于内存,因此 Java 中对象都是存储在内存中,准确地说是 JVM 的堆或栈内存中,可以各个线程之间进行对象传输,但是无法在进程之间进行传输。如果涉及到跨内存的数据传输(比如两台机器的传输),直接把对象作为参数传递就不可取了,这时就需要通过“网络”将数据传输。
举个例子,如果没办法自己亲自把情书送到对方手上,是不是得找一个人送过去?这就是 RPC 相关的知识了。
怎么序列化(How) 上述内容在之前那篇文章里都有涉及,接下来才是本文的重点,在实际使用时我们究竟该怎么序列化,有哪些方式可以序列化?为什么我们在代码中很少遇到手写序列化的情况。这些都是本文要解答的内容。
本文我们以 Java 为例。
JDK 序列化 作为一个成熟的编程语言,Java 本身就已经提供了序列化的方法了,因此我们也选择把他作为第一个介绍的序列化方式。
JDK 自带的序列化方式,使用起来非常方便,只需要序列化的类实现了Serializable接口即可,Serializable 接口没有定义任何方法和属性,所以只是起到了标识的作用,表示这个类是可以被序列化的。如果想把一个 Java 对象变为 byte[]数组,需要使用ObjectOutputStream。它负责把一个 Java 对象写入一个字节流:
...

计算机的世界是由 0 和 1 构成的,为了方便人类与计算机沟通,先贤们发明了编程语言,通过编译器将这些语言翻译成机器可以看懂的机器语言。为了方便人类更好的阅读代码,避免不必要的 996,几乎所有的编程语言都提供「注释」的特性,在某种程度上,这些「注释」的存在就是“废话”,因为编译器在执行到这里的时候是直接忽略的,「注释」虽然是人类写的,却也只是为了给“愚蠢”的人类看的。然而,无论哪个时代都有前行者,他们所做的不过是让我们的代码看起来更简洁,更有时代的进步感,因此必须要让人类与机器的沟通更进一步了,而这就是写给编译器的注释——「注解」。
何为「注解」 所谓注解,英文名 Annotation,是在 Java SE 5.0 版本中开始引入的概念,同class和interface一样,也属于一种类型。很多开发人员认为注解的地位不高,但其实不是这样的。像@Transactional、@Service、@RestController、@RequestMapping、@CrossOrigin 等等这些注解的使用频率越来越高。
说了这么多,到底何为「注解」?
注解是放在 Java 源码的类、方法、字段、参数前的一种特殊“注释”。
话不多说,直接上代码:
// 用户请求接口 @RestController public class UserController { @GetMapping(value = "/user") public User getUser() { return new User("闰土",22,"男"); } } 上述是一个十分简单的 SpringBoot 的控制器代码,第 1 行是「注释」,是告诉阅读这行代码的人这是一个用户请求接口;第 2 行和第 4 行是「注解」,是用来编译器,这一个 Restful 接口,请求方法为 Get,匹配的是"/user"路径。
注释会被编译器直接忽略,注解则可以被编译器打包进入 class 文件,因此,注解是一种用作标注的“元数据”。从 JVM 的角度看,注解本身对代码逻辑没有任何影响,如何使用注解完全由工具决定。
「注解」的本质 在探究「注解」的本质之前,我们要先理解一个东西,Annotation 同class和interface一样,也属于一种类型,因此如果想要申明一个注解的话,我们同样需要写一个 java 文件来创建注解。注解的创建方法很简单,见下面的代码 👇
import java.lang.annotation.*; @Target(ElementType.METHOD) @Retention(RetentionPolicy.SOURCE) public @interface TestOverride { } 如上面代码所示,创建了一个名为「TestOverride」的注解,关键词是**「@interface」**,这时有小伙伴肯定就要说了,为什么我创建一个注解前还有注解?不急,这里我们暂且按下不表,之后来解释。
...

前言 对于云端编程,我想大多数人的第一想法应该是微软推出的 VSCode Remote,这个功能基于开源的 VSCode,通过 SSH 远程连接到服务器,开发者可以通过端口转发、SCP 等一系列实用功能快速实现远程开发。我曾体验过这种编程方式,极大减轻了电脑性能的压力,但我认为这并不是云端编程的最终形态,因为我仍然需要在自己的电脑上安装 VSCode 才可以使用这个功能。
最近 2021 款的 iPad Pro 上市了,这次搭载的是和 Mac 同款的 M1 芯片,性能强大到甚至有让人利用 iPad 编程的想法,只是迫于各大厂商没有推出适配 iPad 的 IDE,便也只能沦为“买钱生产力,买后爱奇艺”的工具了。那么有没有什么办法可以在不安装 IDE 的情况下使用 iPad 编程吗?自然是有的,JetBrains 公司提出了一种新的解决方案:把 IDE 搬进浏览器里。这便是本文的主角——JetBrains Projector。
发展 提起 JetBrains,你会想到什么?各路强大的 IDE,比如 Android Studio、IDEA、WebStorm……这些对于开发者来说耳熟能详的产品都出自这家公司,这些 IDE 的功能强大,但同时也只能运行在用户自己的电脑上,其“内存黑洞”的称号更是让开发者们又爱又恨。
事实上,目前所有的 JetBrains IDE 都使用 Java Swing 绘制 UI,其他基于 IntelliJ 的 IDE 也是如此,比如 Android Studio。鉴于 Swing 是 Java GUI 的一个库,而 Java 本身就是一门很吃内存的编程语言,虽然可以充分利用 Java 跨平台的特性,这也是这些 IDE 在 macOS、Windows 和 Linux 上 UI 几乎一致的原因。但现在,Swing 跨桌面平台的特性却也成为阻碍其发展的一个原因了,在一些瘦客户端的情况下,“内存黑洞”屡屡被人诟病,Swing 也无法发挥其优势,于是 Projector 便应运而生了。
...

3 月 30 日,小米在其新品发布会上公布了他们要造车的消息,那场发布会我看完了,其实这个消息在意料之中,如今的手机市场已经趋向饱和,手机厂商竞争加剧,疯狂内卷,手机业务再进行大的扩张也非易事。
就在这两天,极狐阿尔法 S 也面世了,这辆车上搭载的是华为最新的无人驾驶系统,由此可见,围绕着汽车形成的车联网在未来也会逐渐普及。而我也就是一个写代码的,对于企业的战略布局我不关心,这一篇文章也只是想来聊聊新领域背后的一项老技术——MQTT。
何为 MQTT MQTT 即 Message Queuing Telemetry Transport,中文名为消息队列遥测传输协议,是一种基于发布/订阅模式的"轻量级"通讯协议。其本质上也是构建于 TCP/IP 协议上的一种通信协议,其地位在 OSI 七层网络协议中和 HTTP 协议并列,同属应用层的网络通信协议。
HTTP 协议全称**「超文本传输协议」**,这里的超文本包括 HTML 文件、图片等。因此在设计之初,HTTP 就已经包含了复杂的报文,但我们知道并不是所有的环境都有较好的网络环境,MQTT 的出现正是为了解决这种问题。
MQTT 协议的最大优点在于,可以以极少的代码和有限的带宽,为连接远程设备提供实时可靠的消息服务。也正是因为 MQTT 协议是一种低开销、低带宽占用的即时通讯协议,使其在物联网、小型设备、移动应用等方面有较广泛的应用。
探究 MQTT 的原理 发布/订阅 MQTT 协议是基于客户端-服务器的消息发布/订阅传输协议,在整个通信过程中,有三个重要的角色,分别是发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务端,消息发布者可以同时是订阅者。
代理(Broker) MQTT 中的 Broker 类似于一个中转站,位于消息发布者和订阅者之间。在 Broker 中,可以接受客户发布的应用信息,处理来自客户端的订阅和退订请求以及向订阅的客户转发应用程序消息。Broker 通常由一个应用程序或一台设备充当。
消息组成 在 MQTT 中,传输的消息分为:主题(topic)和负载(payload)两部分:
Topic,可以理解为消息的类型,订阅者订阅(Subscribe)后,就会收到该主题的消息内容。 Payload,可以理解为消息的内容,是指订阅者具体要使用的内容。 最后 本篇文章篇幅较短,主要是为了向大家介绍一下 MQTT 这一协议的基本信息,下一节将会介绍如何搭建一个可用的 MQTT 环境并用实际代码演示如何使用 MQTT 协议。

身份认证 这里所说的身份认证,指的是狭义上的在计算机及其网络系统中确认操作者身份的过程,从而确定用户是否具有访问或操作某种资源的权限。
之所以要在互联网中进行身份认证,是为了防止攻击者假冒你的身份在系统中进行不利于你的操作。试想一下,万一哪天早晨起来你发现你的支付宝账号被盗了,你余额宝里的钱全没了,那岂不是亏大了。
只不过,和现实世界不同的是,网络世界中一切信息都是用一组特定的数据来表示的,计算机只能识别用户的数字身份,所以对用户的授权本质上就是针对用户数字身份的授权。
因此,如何保证操作者的物理身份和数字身份相对应,就成了一个至关重要的议题了,身份认证也因此在互联网世界中起着举足轻重的作用了。本文将会介绍目前很多网站常用的一种方式——双因素认证(也叫两步验证,英语:Two-factor authentication,缩写为 2FA)。
双因素认证 2FA 虽然网络世界和真实世界对于身份的表示不尽相同,但是对于身份认证的手段与经验是可以相互借鉴的。在真实世界,对用户的身份认证基本依据可以分为这三种:
上述三种认证依据被称为三种「因素」(factor)。因素越多,证明力就越强,身份就越可靠。
因此,在网络世界中,为了达到更高的身份认证安全性,某些场景会将上面 3 种挑选 2 种混合使用,即双因素认证。
在支付宝还没有在中华大地普及的时候,去银行通常需要准备一个叫「U 盾」的东西,在使用网上银行时,用户需要先插上 U 盾,然后再输入密码才能登录网上银行。在这一操作中,U 盾(you have)+密码(you know)这两种因素组合在一起就构成了一个双因素认证。
只是后来,随着移动互联网的普及,手机渐渐成为最离不开人身边的物品了,于是传统的「U 盾+密码」的组合方案就被「手机+密码」的组合替代了。
现如今,短信验证码在国内已经成为使用最广泛的两步验证方法之一了,虽然操作方便,不需要安装额外的 APP,但是验证码的下发依赖网络和运营商信号,有被窃听的风险。试想一下,如果这种验证码的获取不需要依赖运营商和网络,哪怕手机处于飞行模式也可以获取验证码,那么安全性是不是就得到提升了?
而这也就是下面将要说的 TOTP,即**“基于时间的一次性密码(Time-based One-time Password)”**。这是目前公认的可靠解决方案,已被纳入国际标准。
TOTP 流程 TOTP 的流程如下:
服务器随机生成一个的密钥,并且把这个密钥保存在数据库中。 服务端将该密钥下发,通常是在页面上显示一个二维码,内容中包含密钥。 客户端扫描二维码,把密钥保存在客户端。 客户端每 30 秒使用密钥和时间戳通过 TOTP 算法生成一个 6 位数字的一次性密码 其实利用 TOTP 验证的流程很简单,这里也只是介绍,如果想深入了解 TOTP 算法的具体实现过程,可以参考 👉 TOTP: Time-Based One-Time Password Algorithm
通过这种方式生成一次性验证码,除去第一次获取服务器下发的密钥外,对网络并无其他要求了,这样即使是在离线情况下也可以使用,而且由于由于这种动态生成的密码通常只会存在 30s,安全性也得到了较大的提升。
只是在实际过程中,肯定要额外考虑一些情况,比如如果有人想要暴力破解验证码时,我们可以对验证的错误次数进行限制;抑或是手机端时间和服务器时间不同步,我们需要通过算法的方式兼容服务器时间的前后 30s,从而有效的避免细微时间上差异而导致的验证失败。
使用现状 目前 TOTP 验证 App 主要分为两类:“独占类”和“开放类”。所谓独占类指的是只支持自家账户登录的两步验证,比如 QQ 安全中心、Steam 验证令牌等。开放类则是一个纯粹的两步验证 App,通过一个 App 去作为多个网站的验证器,例如 Google authenticator 就是一个开源的基于 TOTP 原理实现的一个生成一次性密码的工具。
...