
在回答标题这个问题之前,我们先试想一下,在没有 try…catch 的情况下,如果想要对函数的异常结果进行判断,我们应该怎么做?
异常
第一个想法肯定就是 if…else 了,一般情况下,相关的代码段我们都是放在一起的,如果此时你的程序中有大量的代码段要做这做判断,这就意味着后面执行的逻辑会依赖你前面语句的执行情况,也就意味着你每调用一个可能会出现错误的函数的时候,都要先判断是否成功,然后再继续执行后面的语句。这就会导致你的代码中会充斥着大量的 if…else。 Java 是一门工程性的语言,而工程也是一种艺术,因此采用这样的做法显然是很不优雅的。《Thinking in Java》中提到“badly formed code will not be run.”,意思是结构不优雅的代码不应该被执行,于是一个适用于 Java 的异常处理机制便应运而生了。 Java 的异常处理其目的在于通过使用少于目前数量的代码来简化大型程序,举个简单的例子 🌰 不用 try…catch
FileReader fr = new FileReader("path");
if (fr == null) {
System.err.println("Open File Error");
} else {
BufferedReader br = new BufferedReader(fr);
while (br.ready()) {
String line = br.readLine();
if (line == null) {
System.err.println("Read Line Error");
} else {
System.out.println(line);
}
}
}
用了 try…catch
try {
FileReader fr = new FileReader("path");
BufferedReader br = new BufferedReader(fr);
while (br.ready()) {
String line = br.readLine();
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
很明显我们可以看出来,下面这种写法主线明确,可读性更高。 当然,try…catch 也并不是百利而无一害。如果程序员在代码中滥用了 try…catch,并且没有做好异常处理,很有可能会导致一些 bug 被隐藏,无法跟踪。不过这些不是本文的重点。有兴趣的可以去阅读下《Thinking in Java》的第 12 章「通过异常处理错误」。
单独捕获异常
在探究将异常捕获与循环结合起来之前,我们先看一下单独捕获一个异常会发生什么?
这是一段异常代码
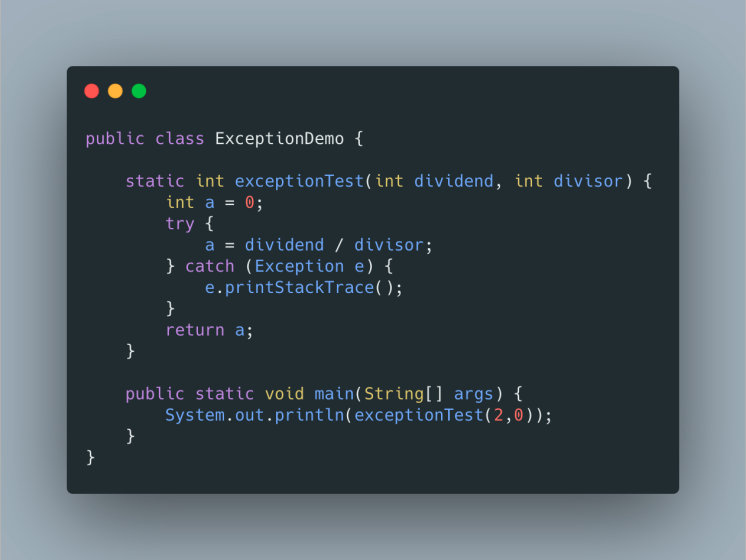 我们用
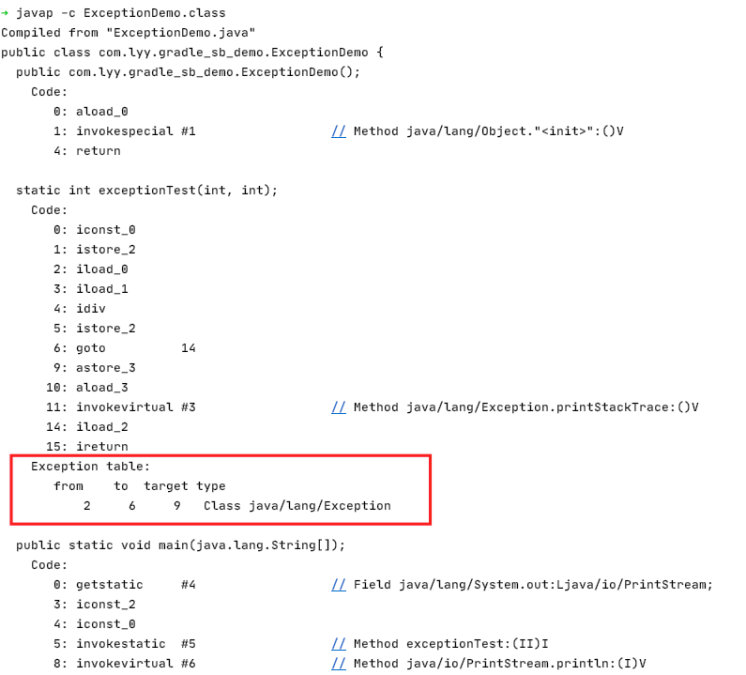
我们用 javap -c ExceptionDemo.class 来打印出他的字节码来看一下
 指令含义不是本文的重点,所以这里就不介绍具体的含义,感兴趣可以到 Oracle 官网查看相应指令的含义 👉The Java Virtual Machine Instruction Set
指令含义不是本文的重点,所以这里就不介绍具体的含义,感兴趣可以到 Oracle 官网查看相应指令的含义 👉The Java Virtual Machine Instruction Set
异常表的四个参数
从输出看,字节码分两部分,code(指令)和 exception table(异常表)两部分。当将 java 源码编译成相应的字节码的时候,如果方法内有 try catch 异常处理,就会产生与该方法相关联的异常表,也就是Exception table:部分。
每一个条目有四列信息: 异常声明的开始行, 结束行, 异常捕获后跳转到的代码计数器(PC)所指向的行数, 还有一个表示捕获的异常类的常量池索引。
那这些信息是从哪来获得的呢?这里我们先来来复习一下 JVM 的相关知识:
 一个线程就是一个栈,由栈帧组成,一个方法就是一个栈帧,内部保存着: 局部变量表、操作数栈、动态链接、方法出口。
JVM 在构造异常实例时需要生成该异常的栈轨迹。这个操作会逐一访问当前线程的栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常等信息。而这些信息就会存储在刚才所说的
一个线程就是一个栈,由栈帧组成,一个方法就是一个栈帧,内部保存着: 局部变量表、操作数栈、动态链接、方法出口。
JVM 在构造异常实例时需要生成该异常的栈轨迹。这个操作会逐一访问当前线程的栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常等信息。而这些信息就会存储在刚才所说的Exception table:中。
四个参数的作用
那刚才所说的那些信息又有什么用呢? 如果在执行方法时有一个异常被抛出, JVM 就会从异常表中按照条目所出现的顺序查找对应的条目。如果异常抛出时 PC 计数器所指向的行数正好落在异常表中某一条目包含的范围内, 并且所抛出的异常正好是异常表中 type 列所指定的异常(或者所指定异常的子类), 那么 JVM 就会将 PC 计数器指向 Target 偏移量所指向的地址, (进入 catch 块)继续执行。 如果没有在异常表中找到异常, JVM 就会将当前栈帧弹出并重新抛出这个异常。当 JVM 弹出当前栈帧的时候, 它就会中止当前方法的执行, 返回到调用当前方法的外部方法中, 不过并不会像正常没有异常发生时那样继续执行外部方法, 而是在外部方法中抛出相同的异常, 这样将会导致 JVM 会在外部方法中重复查询异常表并处理异常的过程。
为什么捕获异常消耗性能
其实从上面的分析中,我们就已经可以理解为什么捕获异常是一个消耗性能的操作了,当你 new 一个 exception 的时候,JVM 已经在 exception 里构建好了所有的 stacktrace:
 现在 Java 领域最火的框架莫过于 Spring 系列了,在一个 web 项目中,调用栈的深度是相当大的,由此可见这里花费的代价是可观的,因此,当你对 stacktrace 不感兴趣的时候,不需要这样的信息时,最好不要随便的 new exception。
现在 Java 领域最火的框架莫过于 Spring 系列了,在一个 web 项目中,调用栈的深度是相当大的,由此可见这里花费的代价是可观的,因此,当你对 stacktrace 不感兴趣的时候,不需要这样的信息时,最好不要随便的 new exception。
异常+for 循环
说了那么多其实都是前置知识,现在我们终于来到了标题提到的问题了。 for 循环和异常有两种结合方式: try+for 循环
public static void tryFor() {
int j = 3;
try {
for (int i = 0; i < 1000; i++) {
Math.sin(j);
}
} catch (Exception e) {
e.printStackTrace();
}
}
for 循环+try
public static void forTry() {
int j = 3;
for (int i = 0; i < 1000; i++) {
try {
Math.sin(j);
} catch (Exception e) {
e.printStackTrace();
}
}
}
首先我先给出结论: 在没有发生异常时,两者性能上没有差异。如果发生异常,两者的处理逻辑不一样,虽然已经不具有比较的意义了,但 for 循环+try 的耗时更明显。
字节码比较
我们对这两种方式进行一个字节码的比较:
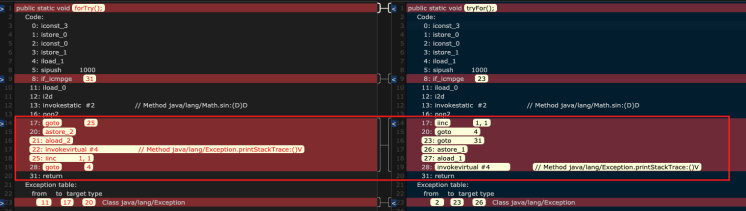 通过第二节的分析我们知道,当程序出现异常时,java 虚拟机就会查找方法对应的异常表,如果发现有声明的异常与抛出的异常类型匹配就会跳转到 catch 处执行相应的逻辑,如果没有匹配成功,就会回到上层调用方法中继续查找,如此反复,一直到异常被处理为止,或者停止进程。而在 for 循环中进行 try…catch 操作,会不断的进行这一过程,性能损耗自然会很恐怖。
通过第二节的分析我们知道,当程序出现异常时,java 虚拟机就会查找方法对应的异常表,如果发现有声明的异常与抛出的异常类型匹配就会跳转到 catch 处执行相应的逻辑,如果没有匹配成功,就会回到上层调用方法中继续查找,如此反复,一直到异常被处理为止,或者停止进程。而在 for 循环中进行 try…catch 操作,会不断的进行这一过程,性能损耗自然会很恐怖。
测试比较
说了这么多我们一直都是纸上谈兵,口说无凭,实际的效果肯定是要跑一下才知道,这里我们采用 Java 的一个微基准测试框架JMH来进行此次测试。 测试结果
Benchmark Mode Cnt Score Error Units
ExceptionDemo.forTry thrpt 20 70.236 ± 8.945 ops/ms
ExceptionDemo.tryFor thrpt 20 85.864 ± 3.272 ops/ms
score 的结果是 xxx ± xxx,单位是每毫秒多少个操作。最终结果也验证了我们的结论。tryFor 的确会比 forTry 更节省性能。
最后
本文从异常出发,分析了单独捕获异常和将异常与 for 循环结合的几种不同的情况,然后通过 JMH 进行了一次测试,最终验证我们标题所说的,不建议在 for 循环里捕捉异常。 当然,try…catch 对性能的影响除了第二节所提到的需要维护一个异常表之外,还有一个原因,那就是 try 块会阻止 java 的优化(例如重排序),try catch 里面的代码是不会被编译器优化重排的。当然重排序是需要一定的条件触发。一般而言,只要 try 块范围越小,对 java 的优化机制的影响是就越小。所以保证 try 块范围尽量只覆盖抛出异常的地方,就可以使得异常对 java 优化的机制的影响最小化。 以上就是本文的全部内容了,如果你觉得有所帮助,不妨点个赞支持一下。
