
这是 2019 年的第一篇文章,因为最近导师给了一个新的任务,有关某 app 的个性化推荐的,正好自己也是第一次学习这方面的知识,便想着汇总整理下。前人栽树,后人乘凉,因为篇幅原因,这一部分准备分开来叙述,本篇主要和大家介绍基于用户的协同过滤算法,希望可以对大家有所帮助,如有谬误,还望指正!
什么是个性化推荐系统?
其实个性化推荐系统早已渗透进我们的生活了,网易云音乐的“每日推荐”,淘宝的”猜你喜欢“,这些都是生活中非常常见的个性化推荐的案例。如今,随着大数据的发展,个性化推荐早已涉及诸多领域,比如电子商务(京东淘宝)、电影和电视网站(youtube)、个性化音乐网络电台(网易云音乐)、社交网络(QQ)、个性化阅读(微信读书)、基于位置的个性化服务(美团)等。推荐算法的本质是通过一定的方式将用户和物品联系起来,而不同的推荐系统也会根据实际情况采取不同的推荐方式。
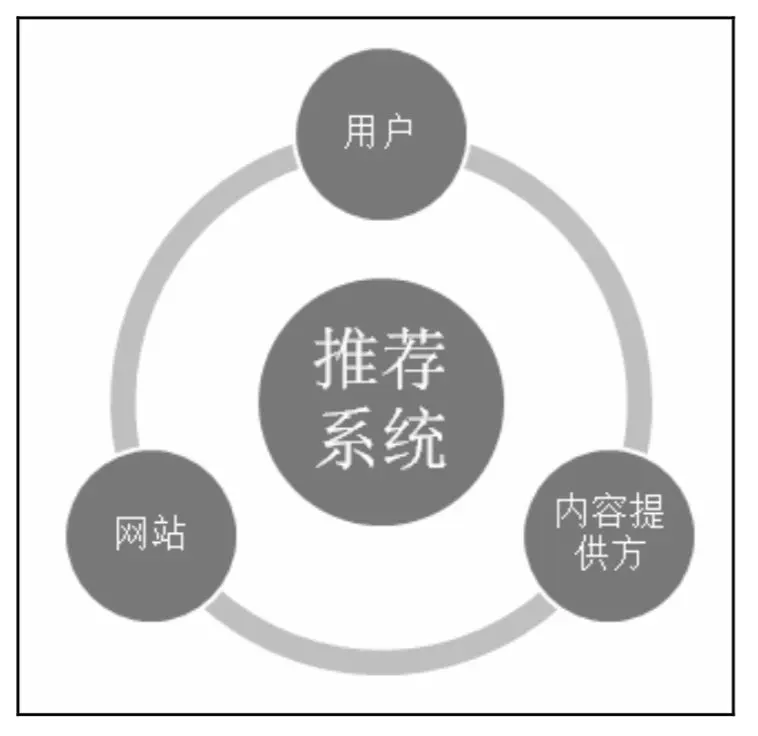
一般来说一个完整的推荐系统一般包括以下三个参与方:
- 被推荐对象
- 推荐物品的提供者
- 提供推荐系统的网站
以网易云音乐的日推为例:
首先,推荐系统需要满足用户的需求,给用户推荐那些令他们感兴趣的音乐。其次,推荐系统要尽量让各个歌手的歌都能够被推荐给对其感兴趣的用户,而不是只推荐几个大流量歌手的歌。最后, 好的推荐系统设计,能够让推荐系统本身收集到高质量的用户反馈,不断完善推荐的质量,增加用户和网站的交互,提高网站的收入。如下图所示:
什么是好的推荐系统?
想要评判一个东西好不好,一定要有个标准。那么推荐系统好坏的标准是什么呢?试想一下为什么大家都喜欢网易云音乐的每日推荐而不喜欢今日头条的每日推送呢?最直观的感受就是网易云的日推歌曲你爱听,而头条的推送你很讨厌。所以说预测准确度是推荐系统领域的重要指标(没有之一)。
好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户发现那些他们可能会感兴趣,但却不那么容易发现的东西(比如网易云音乐经常给你推送那些非常好听但是比较冷门的歌曲)。同时,推荐系统还要能够帮助商家将那些被埋没在长尾中的好商品介绍给可能会对它们感兴趣的用户。
协同过滤(Collaborative Filtering)
为了让推荐结果符合用户口味,我们需要深入了解用户。如何才能了解一个人呢?《论语·公冶长》中说“听其言,观其行”,也就是说可以通过用户留下的文字和行为了解用户兴趣和需求。
实现个性化推荐的最理想情况是用户能主动告诉系统他喜欢什么,比如很久之前注册网易云音乐的时候会让用户选择喜欢什么类型的歌曲,但这种方法有 3 个缺点:首先,现在的自然语言理解技术很难理解用户用来描述兴趣的自然语言;其次,用户的兴趣是不断变化的,但用户不会不停地更新兴趣描述;最后,很多时候用户并不知道自己喜欢什么,或者很难用语言描述自己喜欢什么。
因此,我们需要通过算法自动发掘用户行为数据,从用户的行为中推测出用户的兴趣,从而给用户推荐满足他们兴趣的物品。
基于用户行为分析的推荐算法是个性化推荐系统的重要算法,学术界一般将这种类型的算法称为协同过滤算法(Collaborative Filtering Algorithm)。顾名思义,协同过滤就是指用户可以齐心协力,通过不断地和网站互动,使自己的推荐列表能够不断过滤掉自己不感兴趣的物品,从而越来越满足自己的需求。
既然是基于用户的行为分析,就必须要将用户的行为表示出来,下表给出了一种用户行为的表示方式(当然,在不同的系统中,每个用户所产生的行为也是不一样的),它将个用户行为表示为 6 部分,即产生行为的用户和行为的对象、行为的种类、产生行为的上下文、行为的内容和权重。
| 表示 | 备注 |
|---|---|
| user id | 产生行为的用户的唯一标识 |
| item id | 产生行为的对象的唯一标识 |
| behavior type | 行为的种类(比如说是点赞还是收藏) |
| context | 产生行为的上下文,包括时间和地点等信息 |
| behavior weight | 行为的权重(如果是听歌的行为,那么权重可以是听歌时常) |
| behavior content | 行为的内容(如果是评论行为,那么就是评论的文本) |
随着学术界的大佬们对协同过滤算法的深入研究,他们提出了很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph) 等。在这些方法中,最著名的、在业界得到最广泛应用的算法是基于邻域的方法,而基于邻域的方法主要包含下面两种算法:
- 基于用户的协同过滤算法(User-based Collaborative Filtering),简称 UserCF 或 UCF,这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
- 基于物品的协同过滤算法(Item-based Collaborative Filtering),简称 ItemCF 或 ICF,这种算法给用户推荐和他之前喜欢的物品相似的物品。
基于用户的协同过滤算法
在一个在线个性化推荐系统中,当一个用户 A 需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户 A 没有听说过的物品推荐给 A。这种方法称为基于用户的协同过滤算法。
基于用户的协同过滤算法主要包括两个步骤:
- 找到和目标用户 A 兴趣相似的用户集合。
- 找到这个集合中的用户喜欢的,且目标用户 A 没有听说过的物品推荐给目标用户。
步骤 1 的关键就是计算两个用户的兴趣相似度。这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。
举个栗子 🌰:假设现在有三个用户 A、B、C,已经知道 A 连续 5 天都在听周杰伦和林俊杰的歌,B 连续 5 天在听刘德华和张学友的歌,C 连续听了 5 天林俊杰和张杰的歌,那么你说 A 和谁的兴趣相似度更高,自然是 C。
刚才是你在脑海中思考这个问题的,那如果让机器思考 A 和谁的兴趣相似度更高呢?
其实也很简单,不过在进行下一步的讲解之前,先让我们回顾下基本的数学知识:
在数学中,我们通过测量两个向量的夹角的余弦值来度量它们之间的相似性,两个向量有相同的指向时,余弦相似度的值为 1;两个向量夹角为 90° 时,余弦相似度的值为 0;两个向量指向完全相反的方向时,余弦相似度的值为-1。名曰:“余弦相似性”。最重要的是这一定律不仅仅适用在二维空间,对任何维度的向量空间中都适用,因此余弦相似性常用于高维正空间。例如在信息检索中,每个词项被赋予不同的维度,而一个文档由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
考虑到大多数人可能已经忘了怎么计算余弦相似度了,在这再给大家开个小灶,简单的回顾下计算方法,想要深入了解的,请自行 Google。
假设有二维向量 a,b 如下图所示:
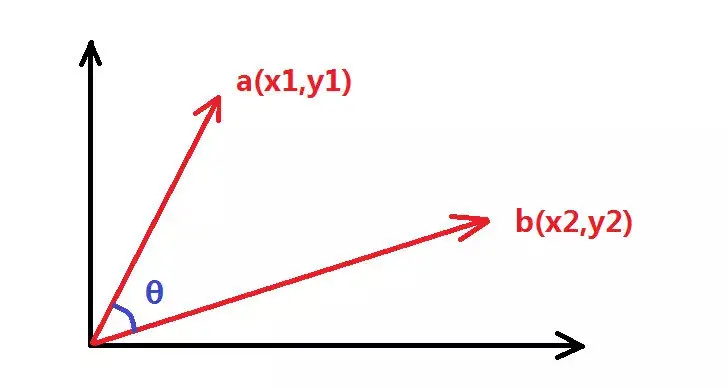
则他们的余弦相似度为:
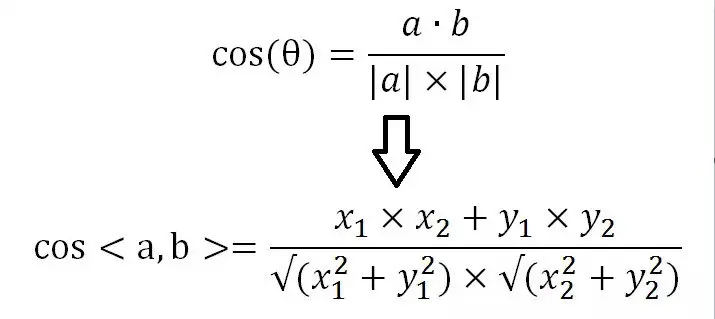
推广到多维向量 $a(a1,a2,a3,a4……)$,$b(b1,b2,b3,b4……)$:
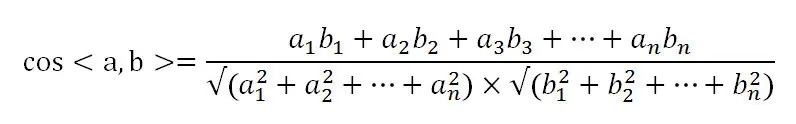
理解了上述数学知识,接下来的就是基本操作了,首先我们先给定两个用户$i$和$j$,令$N(i)$表示$i$ 听过的歌的集合,$N(j)$表示$j$听过的歌的集合,那么$\left | N(i)\bigcap N(j) \right |$就表示$i$、$j$ 都听过的歌的集合,$\left | N(i)\left | \right |N(j) \right |$就表示$i$或 $j$ 听过的歌的集合总数,$W_{ij}$表示用户$i$和用户$j$的相似度。
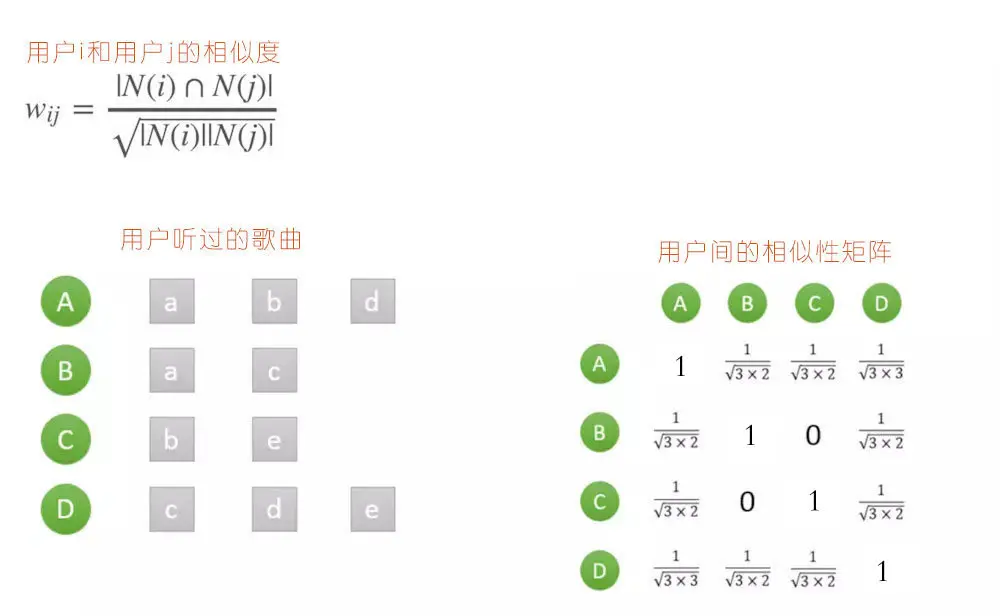
我们来尝试计算下 A 和 D 之间的兴趣相似度:
从**“用户打开过的网页”**可以看出,A 和 D 都听过的歌只有 d,也就是 1 个。用户 A 打开过的网页数=3,用户 D 打开过的网页数=3。所以 A 和 D 的相似度$W_{AD}=\frac{1}{\sqrt{3*3}}=\frac{1}{3}$。其他的计算也是类似的。
在得到用户之间的相似度之后,我们要做的就是解决步骤 2的问题了,假设 e 是刚刚发布的新歌,用户 C 和用户 D 都已经听过了,那么如何计算 A 对新歌 e 的感兴趣程度呢?
得到用户之间的兴趣相似度后,UserCF 算法会给用户推荐和他兴趣最相似的 K 个用户喜欢的物品。如下的公式度量了 UserCF 算法中用户 u 对物品的感兴趣程度:
$$p(u,i)=\sum_{v\in S(u,K)\cap N(i)}^{ }W_{uv}r_{vi}$$
其中,$S (u, K)$包含和用户$ u $兴趣最接近的$ K $个用户,$N (i)$是对物品$ i $有过行为的用户集合,$W_{uv}$是用户$ u$ 和用户$v$ 的兴趣相似度,$r_{vi}$代表用户 $v$ 对物品的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的 $r_{vi}$ =1。
上面一大段截取自《推荐系统实践》,可能很多人看到这公式和这解析有些云里雾里,简单来说就是:
$$p(A,e)=W_{AB}*R_{Be}+W_{AC}*R_{Ce}+W_{AD}*R_{De}$$
其中$P(A,e)$表示 A 对 e 的兴趣度,$W_{AB}$表示 A 与 B 的相似度,$R_{Be}$表示 B 对 e 的兴趣度 ,以此类推。因为我们这里用的不是评分制,而是考虑是否听过这首歌,那么 C 听了 e,C 对 e 的兴趣度就是 1,B 没听过这首歌,所以 B 对 e 的兴趣度为 0。
所以我们可以预测 A 对 e 的相似度为:
$$p(A,e)=\frac{1}{\sqrt{3*2}}1+\frac{1}{\sqrt{33}}*1=\frac{1}{\sqrt{6}}+\frac{1}{3}=0.74158$$
总结
这篇文章从网易云音乐的每日推荐这个生活中很常见的例子,引出了什么是推荐系统,一个好的推荐系统是什么样子的,进而引出协同过滤的概念,并且介绍了什么是基于用户的协同过滤,同时还回顾了余弦相似性等数学知识。然而真正在实际的企业产品中,基于用户的协同过滤并不会这么简单,判断两个用户的相似程度也不是简简单单的使用余弦相似性就可以了,考虑到本文旨在让更多的人对个性化推荐有个简单的概念,本文就不详细展开了,推荐阅读相关的论文,下一篇文章将会介绍基于内容的协同过滤算法。