
“微服务架构是一种将单体应用程序开发为一套小型服务的方法。”——马丁 · 福勒。
首先,我们需要明白什么是单体架构。因此,我将向你展示如何修改它的域,,以便为微服务架构做好准备。最后,我将会简要地告诉你微服务架构的基础知识,并讨论其优缺点。
单体架构 每一种非垂直拆分的架构都是单体架构。软件设计中的垂直拆分意味着将应用程序划分为更多可部署的单元。这并不意味着单体架构不能水平划分。
单体这个词指的是软件的体系结构是由一个后端单元组成。我之所以说后端,是因为我认为单体架构可以在具有多个 UI(如 Web 和移动设备)的同时,仍然可以被看作为一个整体。
组件之间的通信主要通过方法的调用。 如果你的前端和后端是在物理上隔离的,但是它们仍然是一个整体,例如 API 和 Web 客户端。
除非你将后端划分为更多部署单元,否则在我看来你依旧是在使用单体架构。
单域模型 “域是计算机程序的目标主题领域。 形式上,它代表特定编程项目的目标主题。”—— 维基百科
用我的话说,域就是软件存在的原因和目的。我在 3 Domain-Centric Architectures Every Software Developer should Know 这篇文章中写了有关域的几个观点。
下图是一个将在线商城域可视化的结果。
Sales 和 Catalog 子域包含单个的 Product 实体。这种做法是不可取的,因为这将导致一个地方出现更多的问题。这违反了关注点分离原则。
强迫一个实体承担更多的责任,显然是不合理的。实体在这两种上下文中都包含未使用的属性。Sales 不需要知道产品的类别,并且对于 Catalog 来说,知道 Product 是如何将信息传递给客户并没有任何用处。
为了避免这个问题,我们需要找到 Sales 和 Catalog 上下文的边界来将它们分开。这就引出接下来要说的限界上下文。
限界上下文 限界上下文是上下文的边界,参考 [Idapwiki.com](https://ldapwiki.com/wiki/Bounded Context)
要指定限界上下文,我们需要识别出一个模型仍然有效的上下文范围。
我们可以通过对域中的每个实体问一个简单的问题来验证模型,即:这个实体对于哪个上下文有效?
当一个实体对多个上下文有效时,那么它应该被划分到多个上下文中。每个实体都具有与上下文相对应的属性。这一步结束后,你的应用就准备好迁移到微服务架构了。
...

本文翻译自Flutter Could Be the Best Solution for Mobile App Development,如有错误,望批评指正
众所周知,Java 和 Objective-C 是开发高质量 Android 和 iOS App 的首选。大多数开发人员通过这些编程语言制作足够健壮的 APP。
然而,自从 2017 年 5 月 Flutter 横空出世后,几乎所有移动应用开发公司和个人开发者都转向了这种先进的移动应用开发技术。
Flutter 是谷歌的用户界(UI)工具包,从官网介绍中我们可以得知,它可以通过统一的代码为移动端、web 端 和桌面端设计出漂亮的、具有原生 App 特性的应用程序。
Flutter 的引入给移动应用开发行业带来了诸多好处,其中之一就是它简化了跨平台应用的开发过程。
利用 Flutter 开发应用的好处 许多开发者声称他们发现 Flutter 是最有前途的平台。 此外,你现在可以找到许多可靠的公司,他们正在利用 Flutter 为企业提供超现代化、多平台的移动应用程序。
我们无法预测未来,但 Flutter 已经成为一个强大的、可以帮助开发者为 Android 和 iOS 开发移动应用的平台。
Flutter 与一个响应式的现代框架相结合,以便允许开发者可以在 Android 和 iOS 平台上构建令人印象深刻的动画、共享代码库和视图。
上述好处已经证明 Flutter 将会在行业内存活很长时间。但这些并不足以说明 Flutter 的前景和未来是光明的。
下面这些内容你应该了解下,这些是 Flutter 的其他优秀特性。
Flutter 基于 Dart 开发 谷歌开发的 Dart 语言是开发 Flutter 应用的唯一选择。Dart 是一种完全不同的编程语言;它与 Java 惟一相似的地方是语法。 Flutter 强大的编程语言也支持异步操作,这使得开发者可以更轻松地进行应用开发。 另外,在异步操作的支持下,开发人员可以执行那些需要花费时间才能完成的代码,而不会阻塞其他正在运行的代码。
...

Flutter Challenges 是一项尝试利用 Flutter 重新创建特定的应用程序 UI 或设计的挑战。 此次挑战将尝试 Whatsapp Android 应用程序的主界面。 请注意将重点放在 UI 上而不是实际获取消息。
开始 WhatsApp 的主界面包括:
一个带有搜索操作和菜单的 AppBar 在 AppBar 的底部有四个标签 一个用于拍照的相机标签 一个用于多种用途的 FloatingActionButton 一个“聊天”标签可查看所有对话 一个“状态”选项卡可查看所有状态 一个“打电话”选项卡可查看所有的通话记录 ...

介绍 Flutter GridView 几乎与 ListView 相同, 只是它提供了与 ListView 单向视图的 2D 视图比较。 同时它也是移动应用开发中非常受欢迎的小部件。 如果你不相信我, 那就举个例子, 打开你手机中的任何一个电子商务应用, 它肯定是依赖于 ListView 或 GridView 来显示数据的。
Amazon 移动应用程序利用网格显示数据
另一个是 PayTM, 它是印度流行的在线钱包服务应用之一, 它广泛使用网格布局来显示不同的产品
...
**本文翻译自: 《HTTP/2 Frequently Asked Questions》, 如有侵权请联系删除, 仅限于学术交流, 请勿商用。 如有谬误, 请联系指出。 **�
HTTP/2 常见问题解答 以下是有关 HTTP/2 的常见问题解答。
一般问题
为什么要修订 HTTP ? 谁制定了 HTTP/2?? HTTP/2 与 SPDY 的关系是什么? 究竟是 HTTP/2.0 还是 HTTP/2? 和 HTTP/1.x 相比 HTTP/2 的关键区别是什么? 为什么 HTTP/2 是二进制的? 为什么 HTTP/2 需要多路传输? 为什么只需要一个 TCP 连接? 服务器推送的好处是什么? 消息头为何需要压缩? 为什么选择 HPACK? HTTP/2 可以让 cookies (或者其他消息头)变得更好吗? 非浏览器用户的 HTTP 是什么样的? HTTP/2 需要加密吗? HTTP/2 是怎么提高安全性的呢? 我现在可以使用 HTTP/2 吗? HTTP/2 将会取代 HTTP/1.x 吗? HTTP/3 会出现吗? 实现过程中的问题
...
回顾一下 “this” 我们了解到, 在面向对象的 JS 中, 一切都是对象。 因为一切都是对象, 我们开始明白我们可以为函数设置并访问额外的属性。
通过原型给函数设置属性并且添加其他方法非常棒…**但是我们如何访问它们? ! ? ? ? ! **
当他说 “myself” 时, 他的确意味着 ‘this’
我们介绍过 this 关键字。 我们了解到每个函数都会自动获取此属性。 所以这时, 如果我们创建一个有关我们函数执行上下文的抽象模型(我不是唯一一个这么做的人! … 对吗? ! ? ! ), 它看起来就会像这样:
...
目前为止,我们只在 Android 开发中看到 Jetpack Compose。今天,我们将进入一个崭新的阶段,因为 JetBrains 宣布了 IntelliJ 的早期访问版本,允许你使用 Jetpack Compose 来构建 Windows 应用程序。
关于如何使用 Jetpack Compose for desktop,我计划在未来写一些文章加以阐述,本文是这个系列的第一篇文章。上个月,JetBrains 发布了 Compose for desktop Milestone 2,为开发者们带来了更好的开发体验和可操作性。
和往常一样,JetBrains 在继续尝试通过提供独家项目引导来简化开发者的开发流程。在 Compose for desktop 的早期版本中,他们为 IntelliJ 增加了一个桌面项目引导,可以让我们在几秒内配置好项目。
在开始开发之前,你需要安装 IntelliJ IDEA 2020.3 或更高版本。
使用项目模版快速开始 正如我前面所说,项目模板是 IntelliJ 最好用的东西之一。安装完 IDE 后,启动应用程序。你会看到如下的界面:
然后点击顶部栏的 “New Project “按钮,这一操作将会跳转至选择应用程序类型的界面。如下所示:
首先,我们需要从左侧菜单中选择 Kotlin,然后修改项目名称和位置。之后,我们需要选择项目模板。这是配置项目的一个重要步骤。我们需要从项目模板列表中挑选桌面模板,向下滚动就能找到。然后你需要选择项目的 JDK,这里我建议使用 JDK 11。
然后点击“Next”按钮,这将会跳转至确认 Compose 模块的界面。现在点击“Finish”按钮,IntelliJ 将通过自动下载适当的 gradle 为你配置整个项目。
运行你的第一个桌面应用 如果进展顺利,整个桌面项目加载完成后你将会看到以下界面:
此时,你可以运行该应用程序了。由于某些原因,Main.kt 在右上角的“运行”按钮旁边没有被默认选中,所以它会要求你配置项目。为了解决这个问题,你需要在 Main.kt 文件内的主函数旁边点击绿色的“运行”按钮。
运行成功后,你会看到下面的输出结果,有一个包含“Hello, World!”文字的按钮。如果你点击它,按钮里面的文字就会变成“Hello, Desktop!”,来看一下实际体验的效果吧。
...
Post-training 量化是一种可以减小模型大小, 同时降低 3 倍延迟并且仍然能够保持模型精度的一般方法。 Post-training量化将权重从浮点量化为 8 位精度。 此技术在 TensorFlow Lite model converter 中作为一个功能选项被使用。
import tensorflow as tf converter = tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir) converter.post_training_quantize = True tflite_quantized_model = converter.convert() open("quantized_model.tflite", "wb").write(tflite_quantized_model) 在推理时, 权重值从 8 位精度转换为浮点数, 并使用浮点内核进行计算。 此转换只执行一次并进行缓存以减少延迟。
...

概要 这是创建 Slidable 小部件背后的故事(点击这里)。 他是一个当您向左侧或右侧滑动时, 可以在列表项上添加上下文操作的小部件。
这一切是如何开始的呢...
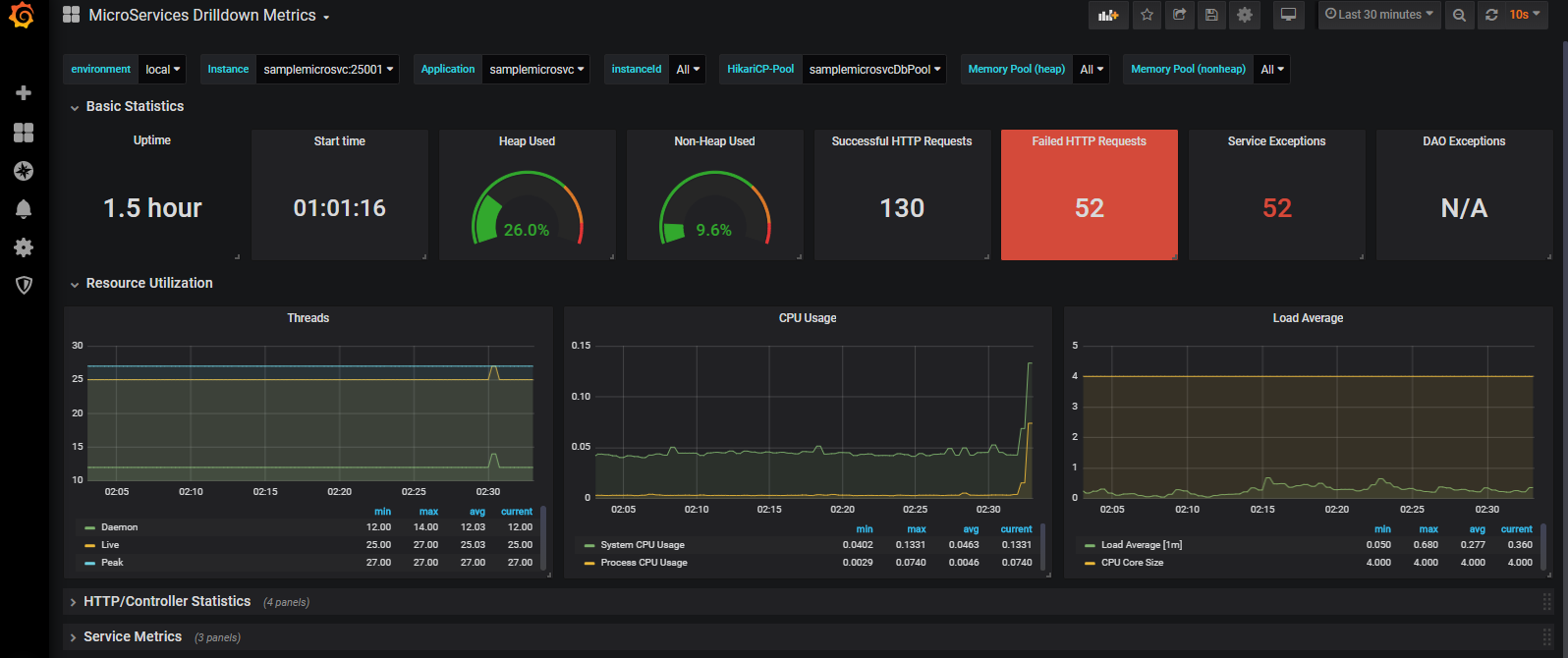
原文地址:Monitor Spring Boot microservices
使用 Micrometer、Prometheus 和 Grafana 为 Spring Boot 微服务构建全面的监控能力
作者:Tanmay Ambre 发布时间:2020 年 3 月 11 日
介绍 在使用微服务和事件驱动架构(EDA)时,包括监控、日志、追踪和警报等方面的可观察性是一个架构十分重要的关注点,主要是因为:
大规模的部署需要集中且自动化的监控与可观测能力 架构的异步性和分布式性质使得关联多个组件产生的指标变得困难 解决这个架构问题可以简化架构管理,并加快解决运行时问题的周转时间。它还有助于做出明智的架构、设计、部署和基础设施,以改善平台的非功能特性。此外,自定义指标的产出、收集和可视化可以为业务或运营带来其他有用的信息。
然而在实际的架构应用中,这个问题经常被忽略。本教程通过使用 Micrometer、Prometheus 和 Grafana 等开源工具对 Java 和 Spring Boot 微服务的可观察性进行监控,相信会成为该方面最佳的实践指南。
先决条件 在你开始本教程之前,你需要设置以下环境:
拥有 Docker Compose 工具的 Docker 环境 一个用于克隆和编辑 git repo 中的代码的 Java IDE 预计时间 完成本教程大约需要 2 个小时。
监控概述 监控工具的主要目标是:
监控应用程序性能 为利益相关者(开发团队、基础架构团队、运营用户、维护团队和业务用户)提供自助服务。 协助进行快速问题溯源分析(RCA) 建立应用程序的性能基线 如果使用云服务,提供云使用成本的监测能力,并以集成的方式监控不同的云服务 监控主要体现在以下四类行为:
应用的 指标化 ——对应用进行指标化带来的指标度量对监控应用和维护团队以及业务用户十分重要。有许多非侵入性的方法来度量指标,最流行的是 “字节码检测”、“面向切面的编程 “和 “JMX”。 指标收集 —— 从应用中收集指标,并将其持久化到相应的存储库中。然后,存储库需要提供一种查询和汇总数据的方法,以实现数据的可视化。市面上流行的收集器有 Prometheus、StatsD 和 DataDaog。大多数指标收集工具是时间序列存储库,并提供高级查询能力。 指标可视化 —— 可视化工具指标查询库,建立视图和仪表盘供最终用户使用。它们提供丰富的用户界面来对指标执行各种操作,例如聚合、数据下探等。 告警和通知 —— 当指标超过定义的阈值(例如 CPU 超过 80% 且持续 10 分钟),可能需要人工干预。为此,告警和通知很重要。大多数可视化工具提供了告警和通知能力。 许多开源和商业产品可用于监控。一些著名的商业产品有:AppDynamics、Dynatrace、DataDog、logdna 和 sysdig。开源工具通常被组合使用。一些非常流行的组合是 Prometheus 和 Grafana、Elastic-Logstash-Kibana (ELK) 和 StatsD + Graphite。
...