找对象的过程中,我竟然理解了什么是机器学习!
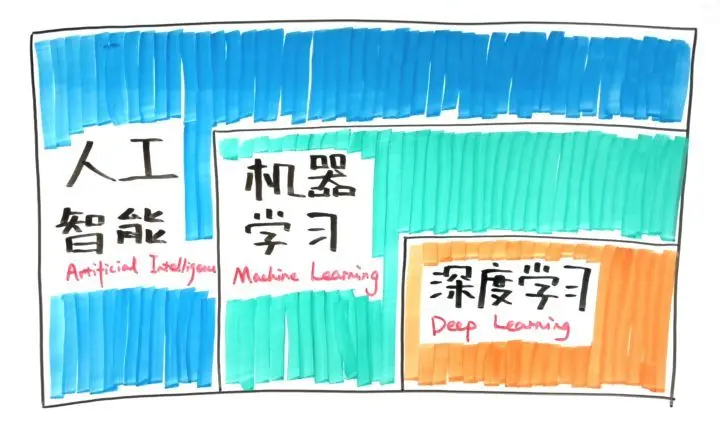
最近开始了有关机器学习方面知识的学习,自己啃书本的时候一些概念枯燥无味,所以借着做笔记的机会来简单理解其中的一些概念,如有谬误,还望指出。😊 什么是人工智能? 我看过很多博客解释什么是人工智能,我觉得还不如一句话一张图解释的简洁明了。让机器实现原来只有人类才能完成的任务,这个操作就是人工智能。 下图所示就是让机器模拟人各种能力的人工智能领域示意图:(图片我是在逛知乎的时候发现的,地址贴在文末) 什么是机器学习? 在解释什么是机器学习之前,我们先来举一个让每个程序员都头疼的问题: 找对象 作为一个程序员,找对象自然是个非常紧迫的问题,那找对象总要有个要求吧 🤔 啥?活的?能动?骨骼轻奇的我怎么可能只有这两点要求啊 🙊 显然我是希望找一个好的女朋友啊(毕竟要带出去撑场面的啊),所以应该怎么找呢? 爱美之心,人皆有之。长得好看的妹子肯定比长得丑的妹子更优秀啊,所以这时我就有了一个简单的规则了:只挑选长得好看的女生的当女朋友。所以还等什么?快去朋友圈看看哪些漂亮的女生还是单身啊。是不是 So easy? 当!然!不!是! 生活总是充满了艰辛 张无忌的麻麻说过: 当你网恋奔现的时候你会发现,那些朋友圈里的都是照骗,你懵逼了。。。很显然,只看女生照片找对象这个方法是很片面的,找到一个好的女朋友的因素有很多而并不只是根据女生的颜值。 在经过了大量思考(并且参考了众多好友的女朋友)之后,你又得出了一个结论:身材好同时颜值高的女生更容易吸引你。同时身材一般但颜值高的好友中只有一半左右能让你感兴趣。 这时你再带着你得出的结论去找女生的时候,才知道原来妹子已经脱单好久,只是把你当朋友。。。但是心好的妹子为了安慰你便把她的闺蜜推给了你。然后你发现你之前的结论不适用了,所以只能重新开始约朋友圈的妹子。 假设过了好久好久之后,你成功的总结了一个找妹子的经验,找到了一个优秀的另你满意的妹子了,你很开心的和她在一起了。丑媳妇也要见公婆的,终于到了你把女朋友带回家给家长见面的时候了,你爸妈说,这女生太漂亮了,你管不住,坚决反对。 在你爸妈的反对下,你只能选择无奈的和妹子 say goodbye👋。最后的最后你和你爸妈摊牌,然后将你的择偶规则告诉你的家人,在他们的筛选下,你终于找到了符合**“所有”**预期标准属性的女朋友了。 是不是觉得很 dan 疼? 回想一下上述的场景,是不是觉得十分 dan 疼,虽然最终结果是你找到了一个满意的女朋友,但是在找对象的过程中,你需要不断的更换标准(属性),而且每当你需要用一个新的标准(属性)去衡量一个妹子的时候,你只能手动更改你自己的规则。并且你需要了解所有繁杂的影响女朋友质量的因素(比如颜值、身材、贴心程度、可爱程度等等)。如果这些因素足够复杂,你很难手动分类所有类型的女生而做出精确的规则。 并且,不断的和不同的女生谈恋爱、试错不仅浪费时间,名声也不好。说不定还会被扣上一定渣男的帽子。 来类比下? 其实上述就是一个非常不典型的机器学习的例子,我们来类比下: 机器学习(ML) 你可以从朋友圈随机挑选一些女生(假设你的异性缘足够的好)作为样本(training data),然后列出所有女生的属性,比如身高、颜值、身材、学历、工作,等等(features),以及是否贴心、黏人度、孝心,等等(output variables)。将这些抽象化的数据在机器学习算法里运行(classification/regression),则 ML 算法构建一个模型:女生的属性——女生的质量。 然后等到下次你又遇见了一个女生了,你就可以用眼睛扫一下检查女生的属性(身材、颜值等)了(test data),然后提供给 ML 算法,他就会根据之前生成的模型(model)预测这个妹子最终和你走到一起的可能有多大。 其实在机器学习构建模型过程中,内部使用的规则也许和上述例子中类似,但是也有可能是更复杂的规则,不过这些你并不需要关心。 你现在再去找对象就有很大信心了,而且更重要的时候,随着时间你的 ML 算法会自我提升(reinforcement learning),当预测错误的时候(恋爱谈不下去就分手)矫正自身,随着读取更多的 training data 预测也会越来越精准。但是,最流弊的一点在于,你可以利用相同的算法而训练出不同的模型(model),找女朋友可以用这个模型,那找秘书呢?(仿佛发现了什么不得了的事情 🤓,随便你想要训练出什么模型只要你高兴就好 ) 所以说对机器学习的最简单的理解,便是: 使用某种算法来对已有数据进行解析、学习,然后对真实世界中的数据/事件作出决策/预测。 那深度学习又是啥? 深度学习,是实现机器学习的技术。对机器学习来说,特征提取并不简单。特征工程往往需要大量的时间去优化,而此时,深度学习便可以自动学习特征和任务之间的关联,还能从简单特征中提取复杂的特征。 深度学习是机器学习的许多方法之一,其他方法包括决策树学习、归纳逻辑程序设计、聚类、强化学习和贝叶斯网络等。 那深度学习是如何寻找那些复杂特征的呢? 他是通过建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,如图象、声音、文本。其产生的灵感来自于大脑的结构和功能,即许多神经元的互联。 下图是我在知乎上看见的一个非常有趣的回答: 推荐大家去阅读下这个回答:👇...